CIFAR10 Classification: TensorFlow + Ray Tune Edition
In this notebook, we turn to hyperparameter tuning using Ray Tune. Our objective is to find better hyperparams and network architecture. Although we will not spend too much time on network architecture, you probably will get enough information to try on your own.
Q: Why would I want to use Ray Tune?
A: If you are already using other Ray products, you know it already. You can easily scale your workload from a single machine to a cluster with ease. You can continue to use your favorite HPO libraries with ray tune, but now you can scale them too.
Author: Katnoria | Created: 03-Oct-2020
1. Imports & Setup
import os
from datetime import datetime
import matplotlib.pyplot as plt
from time import time
import tensorflow as tf
import tensorflow_datasets as tfds
from tensorflow.keras.layers import Dense, Flatten, Conv2D, MaxPool2D, Dropout
from tensorflow.keras.layers import BatchNormalization, Input, GlobalAveragePooling2D
from tensorflow.keras import Model
# tuner
import ray
from ray import tune
from ray.tune.integration.keras import TuneReporterCallback
from ray.tune.schedulers import ASHAScheduler
def version_info(cls):
print(f"{cls.__name__}: {cls.__version__}")
print("Version Used in this Notebook:")
version_info(tf)
version_info(tfds)
version_info(ray)
Version Used in this Notebook:
tensorflow: 2.3.0
tensorflow_datasets: 3.2.1
ray: 0.8.7
print("Num GPUs Available: ", len(tf.config.experimental.list_physical_devices('GPU')))
Num GPUs Available: 1
gpus = tf.config.experimental.list_physical_devices('GPU')
if gpus:
# Restrict TensorFlow to only use the first GPU
try:
tf.config.experimental.set_visible_devices(gpus[0], 'GPU')
logical_gpus = tf.config.experimental.list_logical_devices('GPU')
print(len(gpus), "Physical GPUs,", len(logical_gpus), "Logical GPU")
except RuntimeError as e:
# Visible devices must be set before GPUs have been initialized
print(e)
1 Physical GPUs, 1 Logical GPU
2. Dataset
Tensorflow Datasets already provides this dataset in a format that we can use out of the box.
# Load the dataset
(ds_train, ds_test), metadata = tfds.load(
'cifar10', split=['train', 'test'], shuffle_files=True,
with_info=True, as_supervised=True
)
len(ds_train), len(ds_test), metadata.features['label'].num_classes
(50000, 10000, 10)
Use the built in function to visualise the dataset
# Review metadata
# See https://www.tensorflow.org/datasets/overview
metadata.features
FeaturesDict({
'id': Text(shape=(), dtype=tf.string),
'image': Image(shape=(32, 32, 3), dtype=tf.uint8),
'label': ClassLabel(shape=(), dtype=tf.int64, num_classes=10),
})
NUM_CLASSES = metadata.features["label"].num_classes
num_train_examples = len(ds_train)
num_test_examples = len(ds_test)
print(f"Training dataset size: {num_train_examples}")
print(f"Test dataset size: {num_test_examples}")
Training dataset size: 50000
Test dataset size: 10000
2.1 Plot Images
Next, we plot some images from the training data
examples = ds_train.take(64)
fig, axs = plt.subplots(5, 5, figsize=(8,8))
for record, ax in zip(examples, axs.flat):
image, _ = record
ax.imshow(image)
ax.axis('off')
plt.show()

3. RAY Tune
In the previous notebooks, we manually tried different hyperparameters. Now, we are going to automate that process and use ray to find the best hyperparams.
We need to define the following:
- objective to maximise
- hyperparam search space
- search algorithm to find best hyperparams

Source: https://docs.ray.io/en/latest/tune/key-concepts.html
4. Use Pretrained Models
Instead of training the full model, it is generally a good practice to use a pretrained network as a base model and add your layers on top. This allows us to reduce the training times and leverage on what base model has learned.
4.1 Define Model
We will create our model that will accept hyperparams from the trainer. We are going to determine the best dropout rate, hidden units and activation to use in order to improve the model accuracy
class CIFAR10Model(Model):
def __init__(self, base_model, num_classes, use_gap=False, drop_rate=0.1, hidden_units=128, hidden_activation='relu'):
super(CIFAR10Model, self).__init__()
self.base_model = base_model
self.base_model.trainable = False
self.use_gap = use_gap
self.dropout = Dropout(drop_rate)
self.fc1 = Dense(hidden_units, activation=hidden_activation)
self.fc2 = Dense(num_classes)
def call(self, x):
x = self.base_model(x)
if self.use_gap:
x = GlobalAveragePooling2D()(x)
else:
x = Flatten()(x)
x = self.fc1(x)
x = self.dropout(x)
return self.fc2(x)
4.2 Trainable
This is where you will setup the model initialisation and training. tune.run will run this class instance with different hyperparams based on the config
# Reference: https://docs.ray.io/en/latest/tune/examples/tf_mnist_example.html
class CIFAR10Trainable(tune.Trainable):
def load_data(self, batch_size):
(ds_train, ds_test), metadata = tfds.load(
'cifar10', split=['train', 'test'], shuffle_files=True,
with_info=True, as_supervised=True
)
num_classes = metadata.features["label"].num_classes
train_ds = ds_train \
.cache() \
.shuffle(num_train_examples).batch(batch_size, drop_remainder=True) \
.prefetch(tf.data.experimental.AUTOTUNE)
test_ds = ds_test \
.cache() \
.batch(batch_size, drop_remainder=True) \
.prefetch(tf.data.experimental.AUTOTUNE)
return train_ds, test_ds, num_classes
def setup(self, config):
import tensorflow as tf
IMG_SIZE = 32
BATCH_SIZE = 128
# load data
self.train_ds, self.test_ds, num_classes = self.load_data(BATCH_SIZE)
# model
base_model = tf.keras.applications.ResNet50(input_shape=(IMG_SIZE, IMG_SIZE, 3), include_top=False)
self.model = CIFAR10Model(
base_model,
num_classes,
config.get("use_gap", False),
config.get("drop_rate", 0.1),
config.get("hidden_units", 128),
config.get("activation", "relu")
)
# set loss & optimizer
self.loss_object = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)
self.optimizer = tf.keras.optimizers.Adam(config.get("lr", 1e-3))
# set train and test metrics
self.train_loss = tf.keras.metrics.Mean(name="train_loss")
self.train_accuracy = tf.keras.metrics.SparseCategoricalAccuracy(name="train_accuracy")
self.test_loss = tf.keras.metrics.Mean(name="test_loss")
self.test_accuracy = tf.keras.metrics.SparseCategoricalAccuracy(name="test_accuracy")
@tf.function
def train_step(images, labels):
with tf.GradientTape() as tape:
predictions = self.model(images)
loss = self.loss_object(labels, predictions)
gradients = tape.gradient(loss, self.model.trainable_variables)
self.optimizer.apply_gradients(
zip(gradients, self.model.trainable_variables)
)
# record metric
self.train_loss(loss)
self.train_accuracy(labels, predictions)
@tf.function
def test_step(images, labels):
predictions = self.model(images)
test_loss = self.loss_object(labels, predictions)
# record metric
self.test_loss(test_loss)
self.test_accuracy(labels, predictions)
self.tf_train_step = train_step
self.tf_test_step = test_step
def step(self):
# reset state
self.train_loss.reset_states()
self.train_accuracy.reset_states()
self.test_loss.reset_states()
self.test_accuracy.reset_states()
# train step
for images, labels in self.train_ds:
self.tf_train_step(images, labels)
# test step
for images, labels in self.test_ds:
self.tf_test_step(images, labels)
return {
"epoch": self.iteration,
"loss": self.train_loss.result().numpy(),
"accuracy": self.train_accuracy.result().numpy()*100,
"test_loss": self.test_loss.result().numpy(),
"mean_accuracy": self.test_accuracy.result().numpy()*100,
}
4.3 Setup Config
Config lets us set the hyperparams we want to tune.
Refer docs to find out the list of search space options available.
config = {
"hidden_units": tune.grid_search([32, 64, 128, 256]),
# "drop_rate": tune.quniform(0.0,0.8, 0.2), # says no attribute?
"use_gap": tune.choice([True, False]), # Use Global Average Pooling
"drop_rate": tune.uniform(0, 1),
"activation": tune.choice(['elu', 'relu', 'selu']),
"lr": tune.loguniform(1e-4, 1e-1)
}
# Terminate less promising trials using early stopping
scheduler = ASHAScheduler(metric="mean_accuracy", mode="max")
5. Run Trials
We are now ready to run the trials. You can comment the first two lines. I am doing it in order to access the dashboard over the network.
# shutdown currently running instance
ray.shutdown()
# initialize with the new param
ray.init(dashboard_host="0.0.0.0")
start = time()
# run trials
analysis = tune.run(
CIFAR10Trainable,
config=config,
num_samples=15, # runs 15 jobs with separate sample from the search space
scheduler=scheduler,
stop={"training_iteration": 50},
resources_per_trial={"cpu": 6, "gpu": 1},
ray_auto_init=False
)
stop = time()
took = stop - start
print(f"Total time: {took//60 : .0f}m {took%60:.0f}s")
5.1 Tensorboard
By default, Ray tune records all trials
If you have tensorboard installed, you can see the trial progress as well as hparams there.
tensorboard --logdir ~/ray_results --host 0.0.0.0
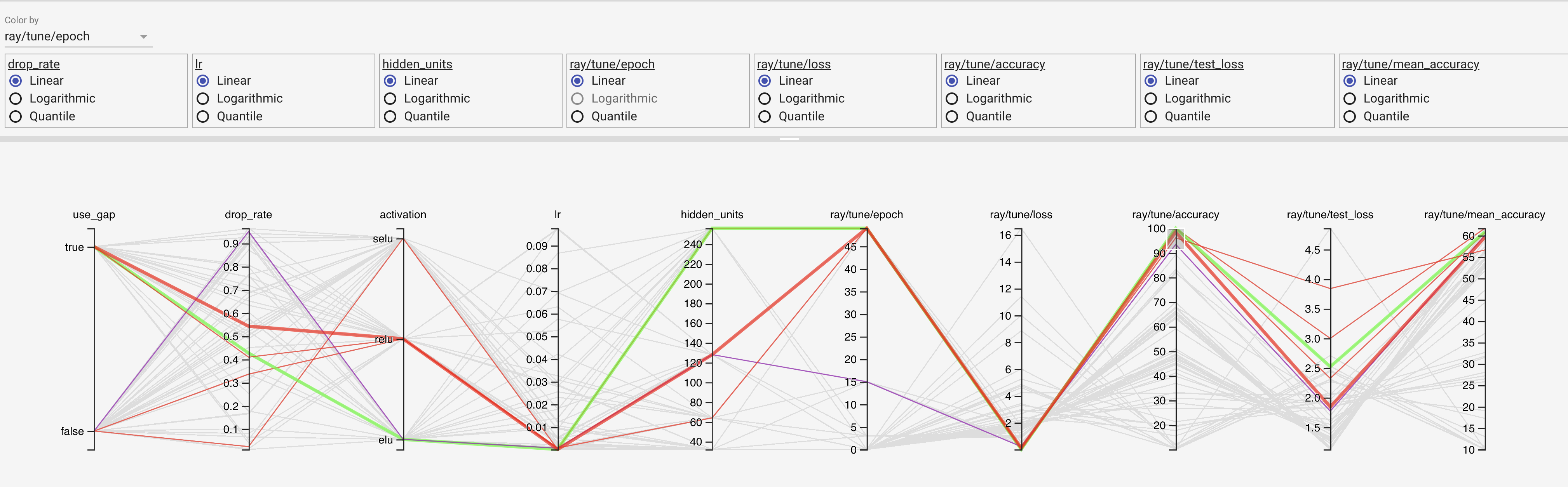
5.2 Dataframe
You could also use the pandas dataframe and review the hyperparam with in this notebook.
df = analysis.dataframe()
df
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
# Best mean accuracy
df['mean_accuracy'].max()
61.70873641967773
# Row with the best mean accuracy
df[df['mean_accuracy'] == df['mean_accuracy'].max()]
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
# best train accuracy
df[df['accuracy'] == df['accuracy'].max()]
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
# save to file
df.to_csv("v1-analysis.csv")
And, that’s it.
You are now ready to take Ray Tune for a spin 🚀.
See also
- Exploration Log of Contrastive Language-Image Pre-training
- 📙 CIFAR-10 Classifiers: Part 7 - Speed up PyTorch hyperparameter search using Ray Tune
- 📙 CIFAR-10 Classifiers: Part 6 - Speed up TensorFlow hyperparameter search using Optuna
- 🍻 💊 Number of People Searching Hangover Cure
- 📙 CIFAR-10 Classifiers: Part 4 - Build a Simple Image Classifier using PyTorch Lightning