Introduction
Last month OpenAI released CLIP - a neural network that learns to map text and images into the same embedding space using contrastive objective and multi-class N-pair loss.
TL;DR
The key ingredients of the architecture are:
- Swappable image and text encoders
- Multi-class N-pair loss
- Contrastive objective, which simplifies the task of learning
So, what can it do?
Authors note that:
CLIP (Contrastive Language–Image Pre-training) can be applied to any visual classification benchmark by simply providing the names of the visual categories to be recognized, similar to the “zero-shot” capabilities of GPT-2 and 3.
Let us take it for a spin?
(Note: This page loads a large number of images)
Q: How well does do OCR?
We start with the hello world dataset of the Neural Networks. The MNIST dataset consists of handwritten images. We want to see if CLIP can identify the digits.

In our queries, we try both the numbers as well as words and find that:
- CLIP has hard time finding most numbers
- query in words performed slightly better
| Query (Numeric) | Result | Query (Word) | Result |
|---|---|---|---|
| 0 | zero | ||
| 1 | one | ||
| 2 | two | ||
| 3 | three | ||
| 4 | four | ||
| 5 | five | ||
| 6 | six | ||
| 7 | seven | ||
| 8 | eight | ||
| 9 | nine |
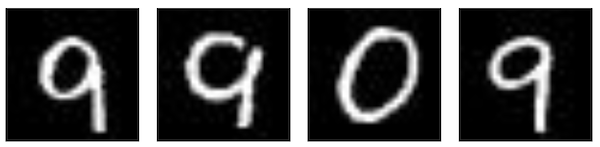
















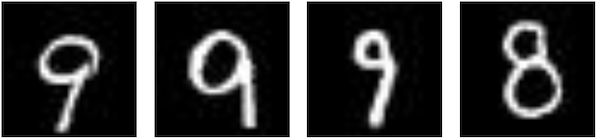


MNIST turned out to be a bit too hard. The authors mentioned it in their paper too.
Next, we will try another dataset - Car License Plate
Yo Craig! I found your car

It can find BAD cars too 😃
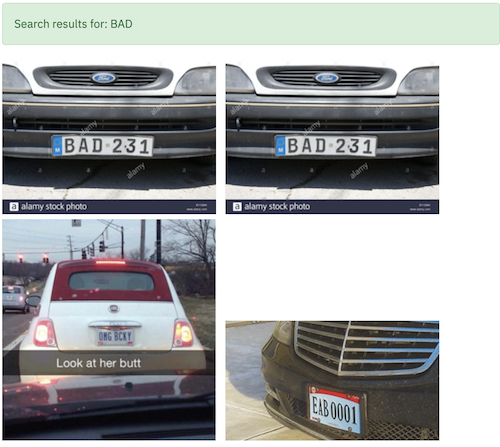
Can it find a real license plate though?

In my tests, I found that it can find numbers but only when they’re clearly visible.
But still.
It is quite cool to see CLIP perform well even though it was not trained on this dataset.
| Query | True Image |
|---|---|


Q: Does it understand colors (and possibly more)?
We continue with the same dataset, Car License Plate, and search for colors and even the make.
Lo and Behold. It knows about the make 🤯

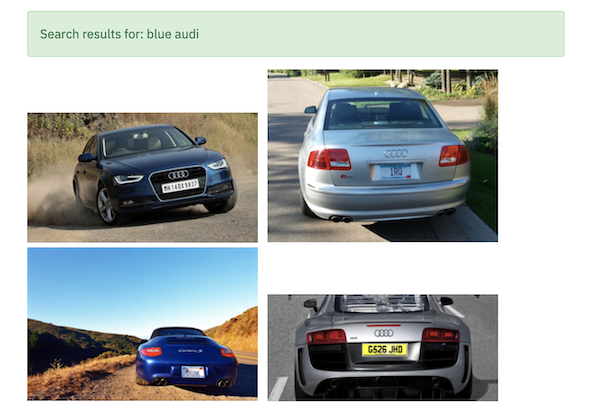
Any Teslas in the house?

At this point, I was tempted to look for Elon Musk and see what we find.

Okay, that was too ambitious and absurd. Lets dial it back.
Surely the dataset will have some Vintage Cars so we try to findout.

Q: Does it understand everyday objects and more?
We will use the 2007 PASCAL VOC dataset and look for certain objects.
We find that CLIP has some understanding or capability to detect activity.

It can associate the activity: riding with the actor: man and subject: bicycle

It can differentiate between a single person and many people doing certain activity

It can also figure out what is countryside

and otherwise a street

It knows about the animals

and, the every day items.

It knows whether the bird is just flying

or flying near the trees.

It knows whether the plane is landing

or mid-air.

The difference between a Fighter Jet and the Passenger Plane
It knows about the cats and dogs

and that Totoro is associated with the cat and not dog or otherwise.

and, where to find Vampire?

How good is it in finding food items?
Dataset: Food101
Yummy pizza on the plate

Pizza in the box

This is a food dataset and I am a Samosa fan, the Indian snack. Lets give it a try.

And at this point, CLIP is like Supa Hot Fire and I am like guy who runs across 🤯🤯

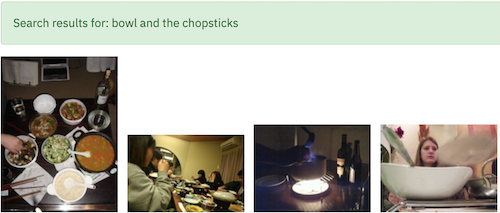
Does it know the difference between Rasgulla and Gulab Jamun.

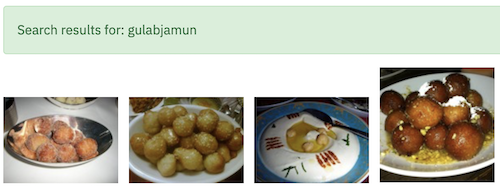
CLIP was trained on 500 million (image,text) pair. It was probably diverse enough to capture details such as the difference between Samosa, Rasgulla, and Gulab Jamun - indian snack and desert.
Penne Pasta or Spaghetti?

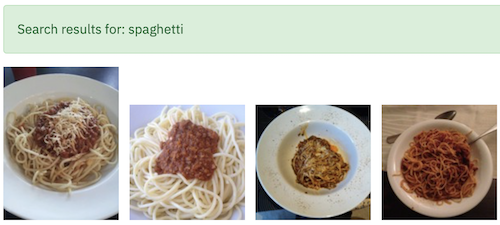
It sure does. It time to move on to the other questions.
Q: Can it recognize (famous) people?
Dataset: Labelled Faces in the Wild










LFW only has a single image of Sachin Tendulkar and the model found it

There is only a single image of RDJ and we see it in the results

Q: I bet it does not know much about the Lego MiniFigures?
Dataset: Lego MiniFigures






I will keep updating this post with what I find
To be continued……
See also
- 📙 CIFAR-10 Classifiers: Part 7 - Speed up PyTorch hyperparameter search using Ray Tune
- 📙 CIFAR-10 Classifiers: Part 6 - Speed up TensorFlow hyperparameter search using Optuna
- 📙 CIFAR-10 Classifiers: Part 5 - Speed up TensorFlow hyperparameter search using Ray Tune
- 🍻 💊 Number of People Searching Hangover Cure
- 📙 CIFAR-10 Classifiers: Part 4 - Build a Simple Image Classifier using PyTorch Lightning